Busca em texto otimizada com a Gem pg_search - Parte II

Na parte I deste post eu expliquei um pouco sobre o conceito e as funcionalidades de Full Text Searching do PostgreSQL e me comprometi a explicar com um projetinho Ruby on Rails através da Gema PgSearch, vamos lá então.

Git clone e diverta-se!
O projeto completo está disponível em https://github.com/callmarx/fts_example. Para executar basta ter o Docker instalado e configurado em seu linux e executar os seguintes comandos em distintos terminais:
# em um terminal, dentro da pasta do projeto
$ make up
# em outro terminal, também dentro da pasta do projeto
$ make prepare-db
Obs: O comando make up ocupa o terminal em questão pois exibe, em tempo real, o log do Rails.
Para sair, basta dar CTRL+C; isso interrompe o rails server, mas o container continuará
rodando em segundo plano (background).
Você pode testar o desempenho das buscas tanto em requisições completas com cURL, Postman ou qualquer outra ferramenta para consulta de API de sua preferência, quanto pelo console da aplicação invocando diretamente os métodos. No final deste post vou compartilhar os resultados que obtive.
Como eu fiz
Primeiro eu montei um Rails API-Only, ou seja, uma aplicação
RESTful que
responde apenas em JSON já que o objetivo aqui é testar buscas em textos e não porque eu não
tenho saco em ficar enfeitando HTML e CSS. Com um único model e controller - Article - sob os
campos :title e :content, podemos preenchê-los com algum texto e assim utilizar a gema.
Para popular esses artigos utilizei o RSS do site da
câmara dos deputados como demonstrado
no script a seguir.
# script disponível em db/seeds.rb
# É executado em "make prepare-db"
require 'rss'
require 'open-uri'
dynamics = %w[
ADMINISTRACAO-PUBLICA
AGROPECUARIA
ASSISTENCIA-SOCIAL
CIDADES
CIENCIA-E-TECNOLOGIA
COMUNICACAO
CONSUMIDOR
DIREITO-E-JUSTICA
DIREITOS-HUMANOS
ECONOMIA
EDUCACAO-E-CULTURA
INDUSTRIA-E-COMERCIO
MEIO-AMBIENTE
POLITICA
RELACOES-EXTERIORES
SAUDE
SEGURANCA
TRABALHO-E-PREVIDENCIA
TRANSPORTE-E-TRANSITO
TURISMO
]
dynamics.each do |dynamic|
url = URI.open("https://www.camara.leg.br/noticias/rss/dinamico/#{dynamic}")
feed = RSS::Parser.parse(url)
feed.items.each do |item|
Article.create(
title: item.title,
content: item.content_encoded,
created_at: item.pubDate
)
end
end
Para utilizar PgSearch no Rails não é
necessário nenhum arquivo de configuração ou inicialização, basta incluir no Gemfile e seguir as
instruções de inclusão e escopo como a documentação da Gema explica em
https://github.com/Casecommons/pg_search#pg_search_scope. Porém, precisamos
configurar nosso banco para o tsvector do PostgreSQL, no caso especificamente para a tabela
articles que contém o texto a ser buscado. Para isso incluí o seguinte migrate:
# Código disponível em db/migrate/20210402195116_add_tsvector_to_article.rb
class AddTsvectorToArticle < ActiveRecord::Migration[6.1]
def up
add_column :articles, :tsv, :tsvector
add_index :articles, :tsv, using: :gin
execute <<-SQL
CREATE TEXT SEARCH CONFIGURATION custom_pt (COPY = pg_catalog.portuguese);
ALTER TEXT SEARCH CONFIGURATION custom_pt
ALTER MAPPING
FOR hword, hword_part, word
WITH unaccent, portuguese_stem;
SQL
execute <<-SQL
CREATE TRIGGER articles_tsvector_update BEFORE INSERT OR UPDATE
ON articles FOR EACH ROW EXECUTE PROCEDURE
tsvector_update_trigger(
tsv, 'public.custom_pt', title, content
);
UPDATE articles SET tsv = (to_tsvector(
'public.custom_pt', title || content
));
SQL
end
def down
execute <<-SQL
DROP TRIGGER articles_tsvector_update
ON articles;
DROP TEXT SEARCH CONFIGURATION custom_pt;
SQL
remove_index :articles, :tsv
remove_column :articles, :tsv
end
end
Traduzindo em passos o migrate acima, temos o seguinte:
- Cria uma nova coluna em articles, chamada tsv do tipo
tsvector - Cria uma indexação sob essa nova coluna do tipo
gin - Cria uma configuração de busca textual copiada da padrão
pg_catalog.portuguesecom nome custom_pt - Edita essa busca textual para mapear as palavras com a extensão
unaccent - Cria um trigger que será invocado na inserção e edição para atualizar o novo campo
:tsvcomtsvectordos campos:title, :contentdo artigo em questão com a nova configuração de busca textual. - Atualiza todos os artigos para preencher
:tsvda mesma forma que o trigger descrito.
Note que com isto utilizei uma estratégia dupla de otimização: tsvector + GIN index.
Os métodos de busca estão no model, sendo .bad_search implementado com o simples ilike
do SQL e .good_search com a gema. O código, disponível em app/models/article.rb, é o
que segue:
# Código disponível em app/models/article.rb
class Article < ApplicationRecord
include PgSearch::Model
scope :ordered, -> { order(created_at: :desc) }
validates :title, presence: true
validates :content, presence: true
pg_search_scope :pg_search,
against: %i[title content],
ignoring: :accents,
using: {
tsearch: {
dictionary: 'custom_pt',
tsvector_column: 'tsv'
}
}
class << self
def bad_search(term)
if term.present?
self.where(
%(
unaccent(title) ilike unaccent(:term)
OR unaccent(content) ilike unaccent(:term)
),
term: "%#{term}%"
)
else
self.all
end
end
def good_search(term)
if term.present?
self.pg_search(term)
else
self.all
end
end
end
end
Atente aqui que foi incluído PgSearch::Model e definido o escopo com pg_search_scope
para que possamos dizer a gema quais configurações de busca estamos utilizando e sob quais campos
do modelo. Defini em ambas os métodos de busca para quando o argumento for nulo retornar .all
de maneira a simplificar a lógica no controller.
Resultados

Antes de pontuarmos o desempenho, vale lembrar que inflexões de palavras como conjugação verbal,
gênero, plural etc, não deveria interferir na integridade da busca, ou seja, no nosso contexto com
essa API, na quantidade de artigos selecionados. Se um usuário busca, por exemplo, por amendoins,
é intuitivo incluir também artigos que contenham a inflexão singular amendoim. Porém, como será
mostrado, este não é o comportamento quando utilizamos ilike da linguagem SQL.
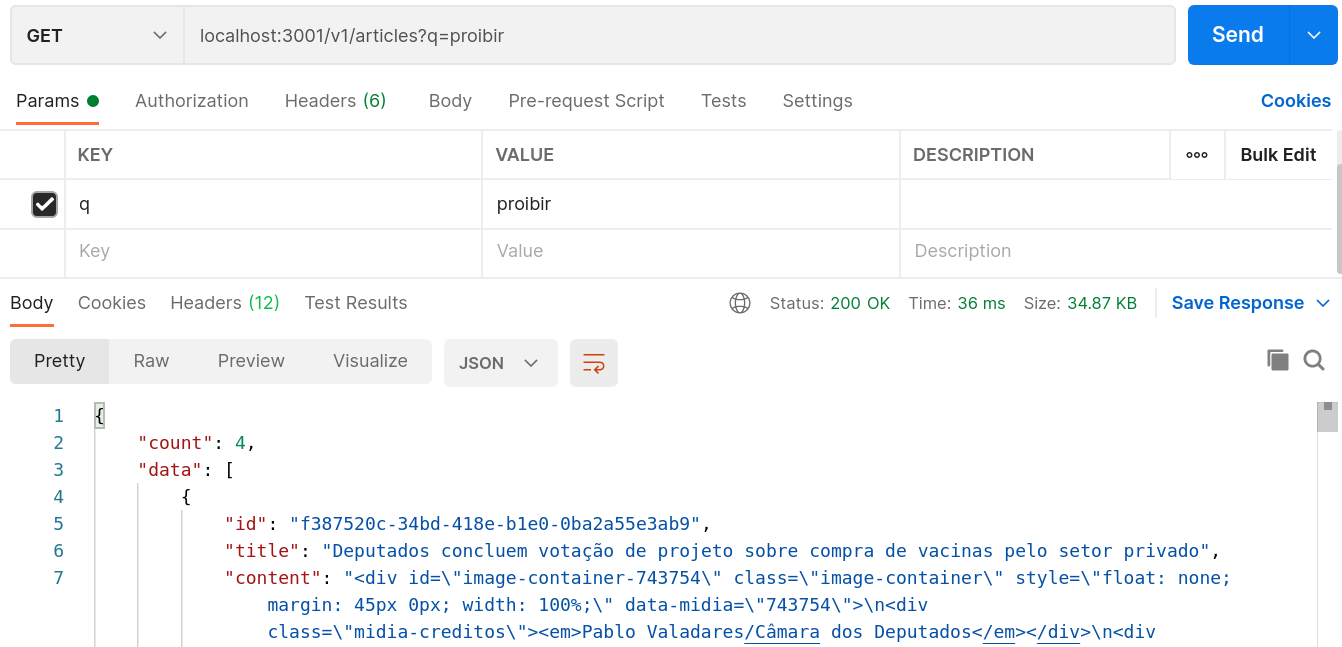
Fazendo uma consulta simples na API (lembrando que é preciso ter um terminal com make up
rodando), sem o parâmetro de url :good_search == 'ok', o controller utiliza o método de busca
.bad_search e fazendo isso para o termo proibir resulta em 4 artigos:
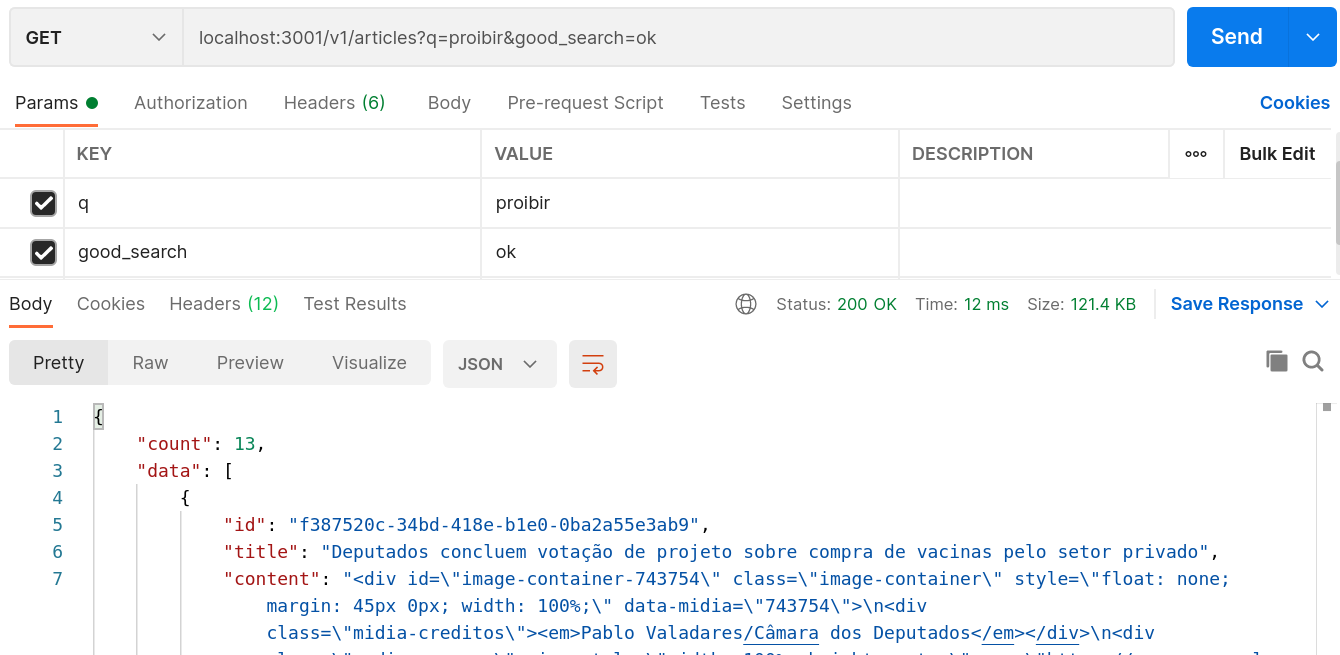
Fazendo agora uma consulta com o parâmetro de url, ou seja, com o método de busca .good_search,
com o mesmo termo proibir, já obtemos 13 artigos:
Se repetirmos as buscas acima com alguma conjugação do mesmo verbo como proibido, a consulta
.bad_search irá selecionar outros artigos, já com a .good_search mantemos os mesmos 13
artigos já que o tsvector trabalha com
lexemas,
o que garante abranger todas as inflexões do termo buscado. Essas consultas pelo Postman podem ser
importadas pelo arquivo
fts_example.postman_collection.json,
também disponível no projeto.
Para avaliar o desempenho implementei algumas tasks para medir o tempo de execução. As buscas são
feitas através de uma
lista de 485 palavras,
explicitamente presentes nos artigos, ou seja, cada uma das palavras retorna pelo menos um artigo
com .bad_search. Dessa forma evitamos consultas vazias com o método ruim, mas presentes com o
método bom, o que afetaria a qualidade do teste. De qualquer forma, como demonstrado anteriormente,
.good_search tende a retornar mais artigos que o outro método, mesmo assim provou-se mais
eficiente como veremos.
Utilizei a gema Benchmark com o código seguinte:
# Código disponível em lib/tasks/benchmark.rake
require 'benchmark'
require 'faraday'
present_words = File.readlines('lib/tasks/present_words.txt').map{ |word| word.chomp }
url = 'http://localhost:3000/v1/articles'
namespace :benchmark do
task method: :environment do
puts "\n########## Method - Gem Benchmark ###########"
Benchmark.bm do |benchmark|
benchmark.report('bad ') do
present_words.each do |word|
Article.bad_search(word).count
end
end
benchmark.report('good') do
present_words.each do |word|
Article.good_search(word).count
end
end
end
end
task request: :environment do
puts "\n########## Request - Gem Benchmark ##########"
Benchmark.bm do |benchmark|
benchmark.report('bad ') do
present_words.each do |word|
Faraday.get(url, { q: word }, { 'Accept' => 'application/json' })
end
end
benchmark.report('good') do
present_words.each do |word|
Faraday.get(url, { q: word, good_search: 'ok' }, { 'Accept' => 'application/json' })
end
end
end
end
task all: :environment do
Rake::Task['benchmark:method'].execute
Rake::Task['benchmark:request'].execute
end
end
Inclui a execução de ambos os testes (método e requisição JSON) no Makefile do projeto, assim basta
executar em seu terminal make benchmark. A seguir os resultados que obtive:
# em um terminal
$ make up
# em outro terminal
$ make benchmark
docker-compose exec api bundle exec rails benchmark:all
########## Method - Gem Benchmark ###########
user system total real
bad 0.314819 0.029698 0.344517 ( 4.853793)
good 0.340305 0.011930 0.352235 ( 0.483992)
########## Request - Gem Benchmark ##########
user system total real
bad 0.399208 0.109991 0.509199 ( 12.725288)
good 0.378955 0.143361 0.522316 ( 4.883817)
Este relatório mostra, em segundos, o tempo de CPU do usuário, o tempo de CPU do sistema, a soma
dos dois anteriores e o tempo real decorrido. Como dependemos do Rails e do PostgreSQL devemos
considerar a última coluna, o tempo real medido. Para reafirmar isso implementei “na mão” outro
benchmark com uso de Process.clock_gettime(Process::CLOCK_MONOTONIC) no lugar de gema
Benchmark, podendo ser executado com make benchmark-manual .
Note a aproximação dos resultados:
$ make benchmark-manual
docker-compose exec api bundle exec rails manual_benchmark:all
######### Method - Manual Benchmark #########
context average total
bad 0.0101s 4.8883s
good 0.0010s 0.4901s
######### Request - Manual Benchmark ########
context average total
bad 0.0253s 12.2896s
good 0.0095s 4.5954s
Dessa forma, podemos observar o poder de tsvector + GIN index. Quando comparado com ilike
o ganho de tempo foi, aproximadamente, de 90% com o método e de 62% com a requisição.