Optimized text search with pg_search gem - Part II

In part I of this post I explained a little about the concept and features of Full Text Searching do PostgreSQL and I committed to explain with a little Ruby on Rails project through PgSearch gem, so let’s go.

Git clone and enjoy it!
The complete project is available at https://github.com/callmarx/fts_example. To run it you just need Docker installed and configured on your linux and run the following commands in different terminals:
# on a terminal, inside the project folder
$ make up
# on another terminal, also inside the project folder
$ make prepare-db
Note: The make up command occupies the terminal in use as it displays in real time the Rails
log. To exit just press CTRL+C; this stops the rails server, but the container will continue
running in the background.
You can test the performance of searches both in complete requests with cURL, Postman or with any other API query tool of your choice, as well as through the application console invoking directly the methods. At the end of this post I will share the results that I’ve got.
How I did it
First I built a Rails API-Only, that is, an application
RESTful that
responds only in JSON since the goal here is to test text searches and not because I wouldn’t
have to handle with HTML and CSS. With a single model and controller - Article and
ArticlesController - under the :title and :content fields, we can fill them with some text and
thus use the gem.
To populate these articles I used RSS from
Brazilian Chamber of Deputies
as shown in the script below.
# script available at db/seeds.rb
# Run it with "make prepare-db"
require 'rss'
require 'open-uri'
dynamics = %w[
ADMINISTRACAO-PUBLICA
AGROPECUARIA
ASSISTENCIA-SOCIAL
CIDADES
CIENCIA-E-TECNOLOGIA
COMUNICACAO
CONSUMIDOR
DIREITO-E-JUSTICA
DIREITOS-HUMANOS
ECONOMIA
EDUCACAO-E-CULTURA
INDUSTRIA-E-COMERCIO
MEIO-AMBIENTE
POLITICA
RELACOES-EXTERIORES
SAUDE
SEGURANCA
TRABALHO-E-PREVIDENCIA
TRANSPORTE-E-TRANSITO
TURISMO
]
dynamics.each do |dynamic|
url = URI.open("https://www.camara.leg.br/noticias/rss/dinamico/#{dynamic}")
feed = RSS::Parser.parse(url)
feed.items.each do |item|
Article.create(
title: item.title,
content: item.content_encoded,
created_at: item.pubDate
)
end
end
To use PgSearch in Rails no
configuration or initialization file is needed, just include it in the Gemfile and follow the
instructions from inclusion and scope as the gem documentation explains in
https://github.com/Casecommons/pg_search#pg_search_scope. However, we need to
configure our PostgreSQL database to tvector, in this case specifically for the table
articles containing the text to be searched. For this I included the following migration:
# Code available at db/migrate/20210402195116_add_tsvector_to_article.rb
class AddTsvectorToArticle < ActiveRecord::Migration[6.1]
def up
add_column :articles, :tsv, :tsvector
add_index :articles, :tsv, using: :gin
execute <<-SQL
CREATE TEXT SEARCH CONFIGURATION custom_pt (COPY = pg_catalog.portuguese);
ALTER TEXT SEARCH CONFIGURATION custom_pt
ALTER MAPPING
FOR hword, hword_part, word
WITH unaccent, portuguese_stem;
SQL
execute <<-SQL
CREATE TRIGGER articles_tsvector_update BEFORE INSERT OR UPDATE
ON articles FOR EACH ROW EXECUTE PROCEDURE
tsvector_update_trigger(
tsv, 'public.custom_pt', title, content
);
UPDATE articles SET tsv = (to_tsvector(
'public.custom_pt', title || content
));
SQL
end
def down
execute <<-SQL
DROP TRIGGER articles_tsvector_update
ON articles;
DROP TEXT SEARCH CONFIGURATION custom_pt;
SQL
remove_index :articles, :tsv
remove_column :articles, :tsv
end
end
Breaking down the migration above into steps, we have the following:
- Creates a new column in
articles, called tsv of typetsvector, - Create an index under this new column of type
gin, - Creates a textual search configuration copied from the default
pg_catalog.portuguesewith name custom_pt, - Edit this textual search to map words with the extension
unaccent, - Creates a trigger that will be invoked on insertion and editing to update the new
:tsvfield withtsvectorfrom the:title, :contentfields of the article in question with the new searching textual configuration. - Updates all articles to populate
:tsvin the same way as the trigger described.
Note that with this I used a double optimization strategy: tsvector + GIN index.
The search methods are in the model, which .bad_search being implemented with simple SQL ilike
and .good_search with the gem. The code, available at app/models/article.rb, is as follows:
# Code available at app/models/article.rb
class Article < ApplicationRecord
include PgSearch::Model
scope :ordered, -> { order(created_at: :desc) }
validates :title, presence: true
validates :content, presence: true
pg_search_scope :pg_search,
against: %i[title content],
ignoring: :accents,
using: {
tsearch: {
dictionary: 'custom_pt',
tsvector_column: 'tsv'
}
}
class << self
def bad_search(term)
if term.present?
self.where(
%(
unaccent(title) ilike unaccent(:term)
OR unaccent(content) ilike unaccent(:term)
),
term: "%#{term}%"
)
else
self.all
end
end
def good_search(term)
if term.present?
self.pg_search(term)
else
self.all
end
end
end
end
Note here that PgSearch::Model has been included and scoped with pg_search_scope so that we can
tell the gem which search settings we are using and under which model fields. I defined in both
search methods to return .all when the argument is null in order to simplify the logic in the
controller.
Results

Before scoring the performance, it is worth remembering that word inflections such as verb
conjugation, gender, plural, etc should not interfere in the integrity of the search, that is, in
our context with this API, in the number of articles selected. If a user searches, for example,
for peanuts, it is intuitive to also include articles that contain the singular inflection
peanut. However, as will be shown, this is not the behavior when using ilike in the SQL language.
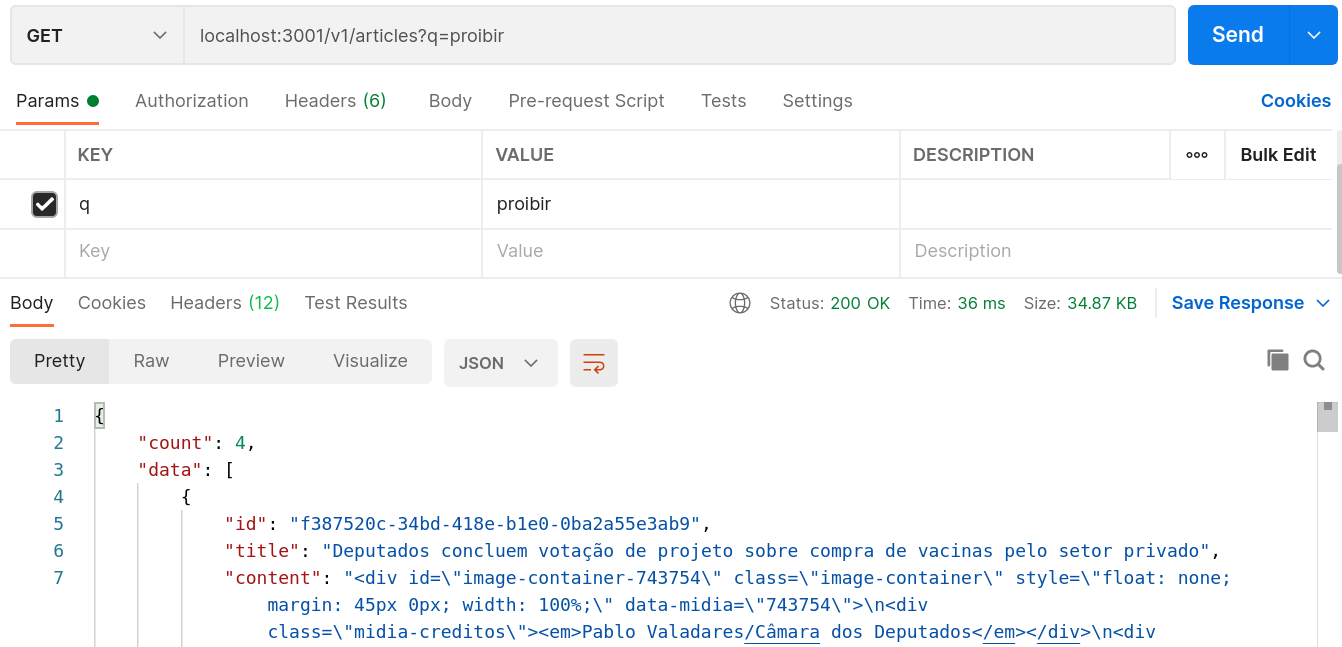
Making a simple query on the API (remembering that you need to have a terminal with make up
running), without the url parameter :good_search == 'ok', the controller uses the .bad_search
method and doing this for the term “proibir” (a Portuguese word meaning forbid) results in 4
articles:
Doing now a query with the url parameter, that is, with the .good_search method, with the same
term prohibit, we already obtain 13 articles:
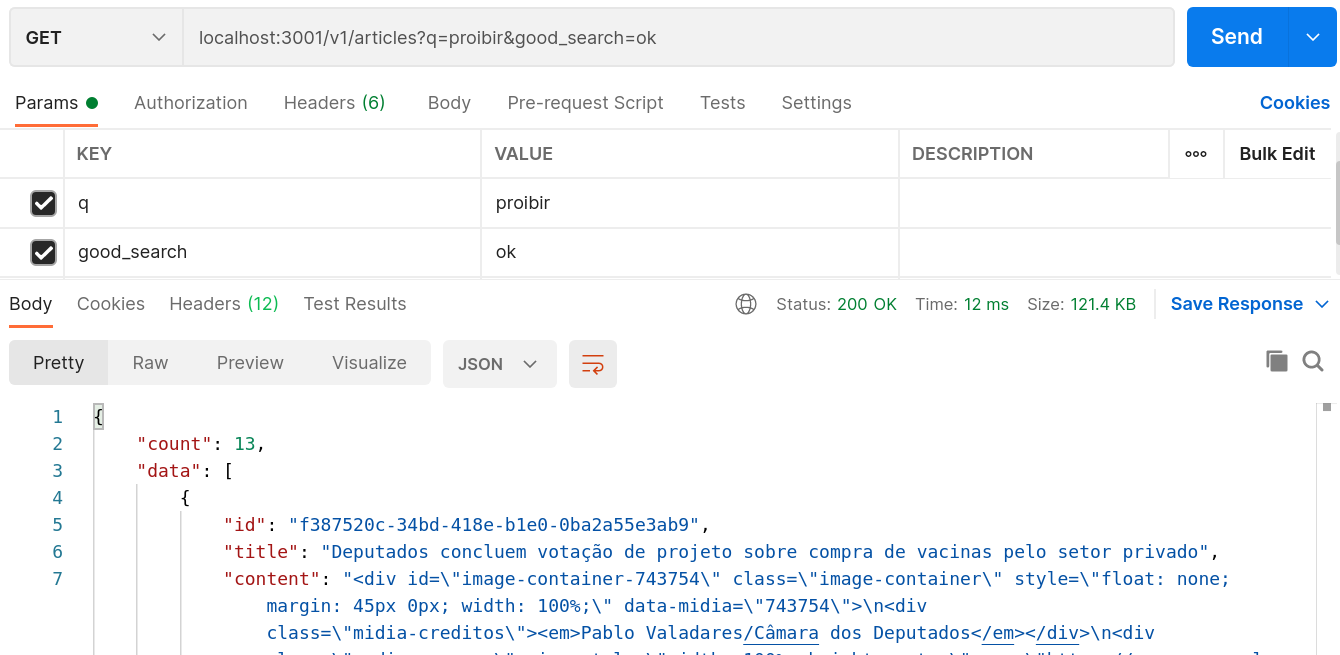
If we repeat the searches above with some conjugation of the same verb as “proibido” (equivalent
of forbidden in Portuguese), the query .bad_search will select other articles, whereas with
.good_search we keep the same 13 articles since tsvector works with lexemes,
what guarantees to cover all the inflections of the term searched. These Postman queries can be
imported by the file fts_example.postman_collection.json,
also available in the project.
To evaluate the performance I implemented some tasks to measure the execution time. Searches are
performed using a list of 485 words,
explicitly present in the articles, that is, each of the words returns at least one article with
.bad_search. This way we avoid empty queries with the bad method, but present with the good
method, which would affect the quality of the test. However, as demonstrated earlier,
.good_search tends to return more articles than the other method, yet it has proven to be more
efficient as we will see.
I used the Benchmark gem with the following code:
# Code available at lib/tasks/benchmark.rake
require 'benchmark'
require 'faraday'
present_words = File.readlines('lib/tasks/present_words.txt').map{ |word| word.chomp }
url = 'http://localhost:3000/v1/articles'
namespace :benchmark do
task method: :environment do
puts "\n########## Method - Gem Benchmark ###########"
Benchmark.bm do |benchmark|
benchmark.report('bad ') do
present_words.each do |word|
Article.bad_search(word).count
end
end
benchmark.report('good') do
present_words.each do |word|
Article.good_search(word).count
end
end
end
end
task request: :environment do
puts "\n########## Request - Gem Benchmark ##########"
Benchmark.bm do |benchmark|
benchmark.report('bad ') do
present_words.each do |word|
Faraday.get(url, { q: word }, { 'Accept' => 'application/json' })
end
end
benchmark.report('good') do
present_words.each do |word|
Faraday.get(url, { q: word, good_search: 'ok' }, { 'Accept' => 'application/json' })
end
end
end
end
task all: :environment do
Rake::Task['benchmark:method'].execute
Rake::Task['benchmark:request'].execute
end
end
It includes the execution of both tests (method and JSON request) in the project’s Makefile, so
just run make benchmark in your terminal. Here are the results I got:
# on one terminal
$ make up
# one other terminal
$ make benchmark
########## Method - Gem Benchmark ###########
user system total real
bad 0.314819 0.029698 0.344517 ( 4.853793)
good 0.340305 0.011930 0.352235 ( 0.483992)
########## Request - Gem Benchmark ##########
user system total real
bad 0.399208 0.109991 0.509199 ( 12.725288)
good 0.378955 0.143361 0.522316 ( 4.883817)
This report shows, in seconds, the user’s CPU time, the system’s CPU time, the sum of the previous
two and the actual elapsed time. As we depend on Rails and PostgreSQL we must consider the last
column, the actual measured time. To reaffirm this I implemented “by hand” another benchmark using
Process.clock_gettime(Process::CLOCK_MONOTONIC) instead of using Benchmark
gem, which can be run with make benchmark-manual. Note the approximation of the results:
$ make benchmark-manual
######### Method - Manual Benchmark #########
context average total
bad 0.0101s 4.8883s
good 0.0010s 0.4901s
######### Request - Manual Benchmark ########
context average total
bad 0.0253s 12.2896s
good 0.0095s 4.5954s
So we can see the power of tsvector + GIN index. When compared to ilike, the time
saving was approximately 90% with the method and 62% with the request.